정리 : Deep Unsupervised Learning
Machine Learning에 대해 공부하신 분이라면 ML을 Supervised Learning, Unsupervised Learning, Reinforcement Learning으로 나누는 그림을 다양한 형태로 보셨으리라 생각됩니다.
여기서 Unsupervised Learning이란 Supervised Learning과는 다르게 Label이 없는 데이터로 학습하는 방식을 말하고, 대표적으로 Clustering(ex. K-means)과 Dimensionality Reduction(ex. PCA)이 있는데요.
이런 내용이 Deep Neural Network를 활용하는 딥러닝에선 좀 더 확장될 수 있습니다.
이 포스트에선 UC Berkeley에서 작년에 진행된 “Deep Unsupervised Learning” 강의를 참고하여 최근 핫한 Deep Learning에서의 Unsupervised Learning이 가지는 의미와 활용 영역에 대해 정리해보았습니다.
Deep Unsupervised Learning
앞에 Deep이 붙었지만 Label이 없는 데이터로 학습을 한다는 개념 자체는 같고, 학습을 하기 위한 모델 Architecture가 DNN이라는 점에서 K-means, PCA 등과 차이가 있습니다. Unsupervised Learning으로 DNN을 학습하는 방법은 크게 두 가지로 나눌 수 있습니다.
- Generative model
- Self-supervised Learning
먼저, Generative model은 말 그대로 GAN, VAE 같은 생성모델을 의미합니다. 본 목적 그대로 Input에는 없지만 Input에 있을법한 이미지를 생성하는 목적으로 사용할 수도 있고, Generative model을 통해 학습한 Input의 유의미한 feature를 downstream task에서 활용할 수도 있습니다. Self-supervised Learning은 Label이 없는 대신 학습의 방향을 결정할 만한 pretask를 설정하고 이에 맞게 Supervised Learning을 진행하는 형태가 됩니다. 두 가지 방식 모두 Input의 유의미한 representation을 학습할 수 있다는 점에서 Unsupervised Learning 외에도 semi-supervised learning, transfer learning 등에도 활용도가 높습니다.
Why Unsupervised Learning ?
그럼, 왜 Unsupervised Learning을 사용해야 할까요?
이 포스트를 작성하게 된 계기이자 가장 많이 참고한 자료가 UC Berkeley 강의(Reference 참조)인데요. 이 강의의 표현을 빌리자면 한 문장으로 다음과 같습니다.
“Ideal Intelligence is all about compression(finding all patterns)”
“finding all patterns”은 Input에 대한 short description을 찾는다는 의미입니다. 이는 유의미한 representation을 딥러닝 모델을 통해 학습하는 것으로 이해할 수 있고, Supervised Learning의 경우 Input을 사람에 의해 주어진 Label에 맞게 학습하기에 학습되는 representation이 제한적일 수 밖에 없습니다.
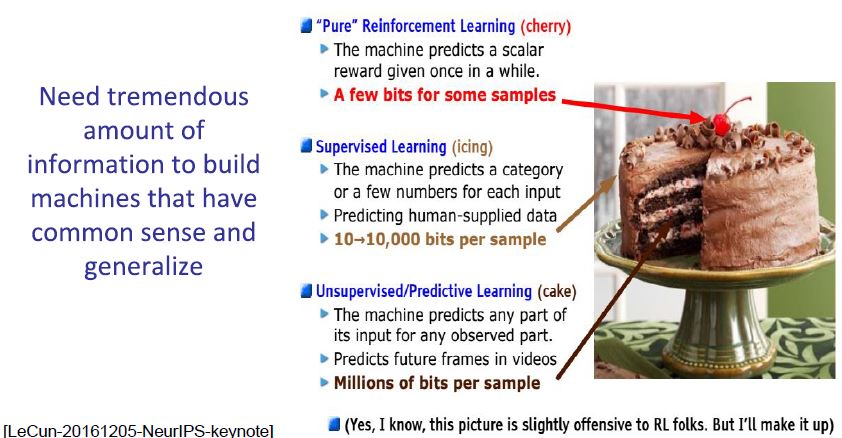
위 그림은 강의 중 “LeCake”으로 언급된 사진과 함께 Reinforcement Learning, Supervised Learning, Unsupervised Learning에 대해 설명하는 페이지 입니다.
잘 학습된 모델 하나를 학습하기 위해선 많은 양의 정보가 필요하고 Unsupervised Learning은 다른 두 방식에 비해 데이터당 사용할 수 있는 정보가 수백만가지 이상으로 많다고 말하고 있습니다.
즉, Unsupervised Learning이 “finding all patterns”에 가장 근접한 방식이라는 것입니다.
Applications
마지막으로 Deep Unsupervised Learning의 활용 영역 입니다.
Generate novel data
학습에 사용되지 않았지만 실제 학습데이터와 유사한 novel data를 생성할 수 있습니다. GAN, VAE 등이 일반적입니다.

Conditional Synthesis Technology (WaveNet, GAN-pix2pix)
DNN feature를 통해 Input 데이터를 다양한 형태로 합성, 노이즈제거, style transfer 등이 가능합니다.
아래는 말을 얼룩말로 변환환 cycle-gan의 결과입니다.

Compression
이미지 파일의 확장자로 잘 알려진 jpeg, png는 압축 방식에 따라 구분되는데요. 이렇게 잘 알려진 압축방식보다 DNN을 통한 압축의 성능이 더 좋다고 합니다.
아래는 Lossy 압축방식으로 JPEG와 WaveOne 방식을 비교한 것입니다.

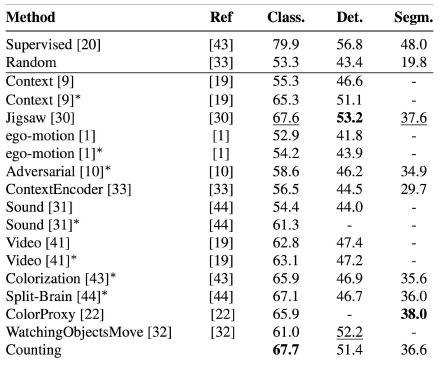
Improve any downstream task with unsupervised pre-training
Supervised Learning의 성능 및 학습속도 향상을 위해 pre-trained 모델이 일반적으로 사용되는데, unsupervised learning을 통해 이미지의 representation을 잘 학습한 pre-trained모델을
transfer learning하여 detection, segmentation모델을 학습하였을 때 성능이 많이 사용되는 ImageNet pre-trained 모델보다 좋다는 결과가 있습니다.
이는 pre-trained 모델을 위해 꼭 Labeled data가 필요하지 않음을 보여주는 의미있는 결과라 생각됩니다.
Reference
L1 Introduction – CS294-158-SP20 Deep Unsupervised Learning – UC Berkeley, Spring 2020
Title_img : https://quoracreative.com/article/machine-learning-marketing-Sales