논문 리뷰 : Bootstrap Your Own Latent A New Approach to Self-Supervised Learning
이번 논문은 Image Representation Learning에서 SimCLR과 MoCo의 성능을 모두 뛰어넘었다고 하는 BYOL 입니다. Google DeepMind와 Imperial College에서 발표하였고, 기존 연구들에 비해 Supervised Learning 성능(ResNet50, ImageNet acc 기준)에 가장 근접한 결과를 보여주고 있습니다.
Intro
Image representation learning 및 Unsupervised learning 분야에서 MoCo, SimCLR 등이 높은 성능을 보여주었지만, 이러한 선행 연구들에선 공통적으로, 적절한 augmentation의 사용과 학습 과정에서 많은 negative sample을 보는 것이 중요했습니다. 각 연구들에선 ImageNet data에 대해 실험을 통해 적절한 Augmentation과 batch size를 설정했지만, 이 값들은 data domain에 따라 달라질 수 있는 값들입니다. 즉, custom data에 적용할 경우, 대량의 Unlabeled data와 소량의 Labeled data를 사용한 Semi-Supervised Learning을 적용한다고 생각하면, 적절한 Augmentation 선정과 사용가능한 resource 내에서 batch size의 설정 등이 많은 실험을 필요로 할 것입니다.
이 논문에선 이전 연구들에 비해 batch size와 augmentation에 대한 robustness를 증가시키면서, Image representation learning 성능도 개선된 결과를 보여줍니다. 특히, 학습 과정에서 negative sample을 전혀 사용하지 않았다는 점이 이전 연구와는 가장 큰 차이라고 할 수 있습니다. 두 개의 neural network을 사용하고 이 중 하나를 target network로 사용하는 것이 핵심 아이디어 입니다.
Methods
논문의 motivation은 간단한 실험에서 출발합니다.
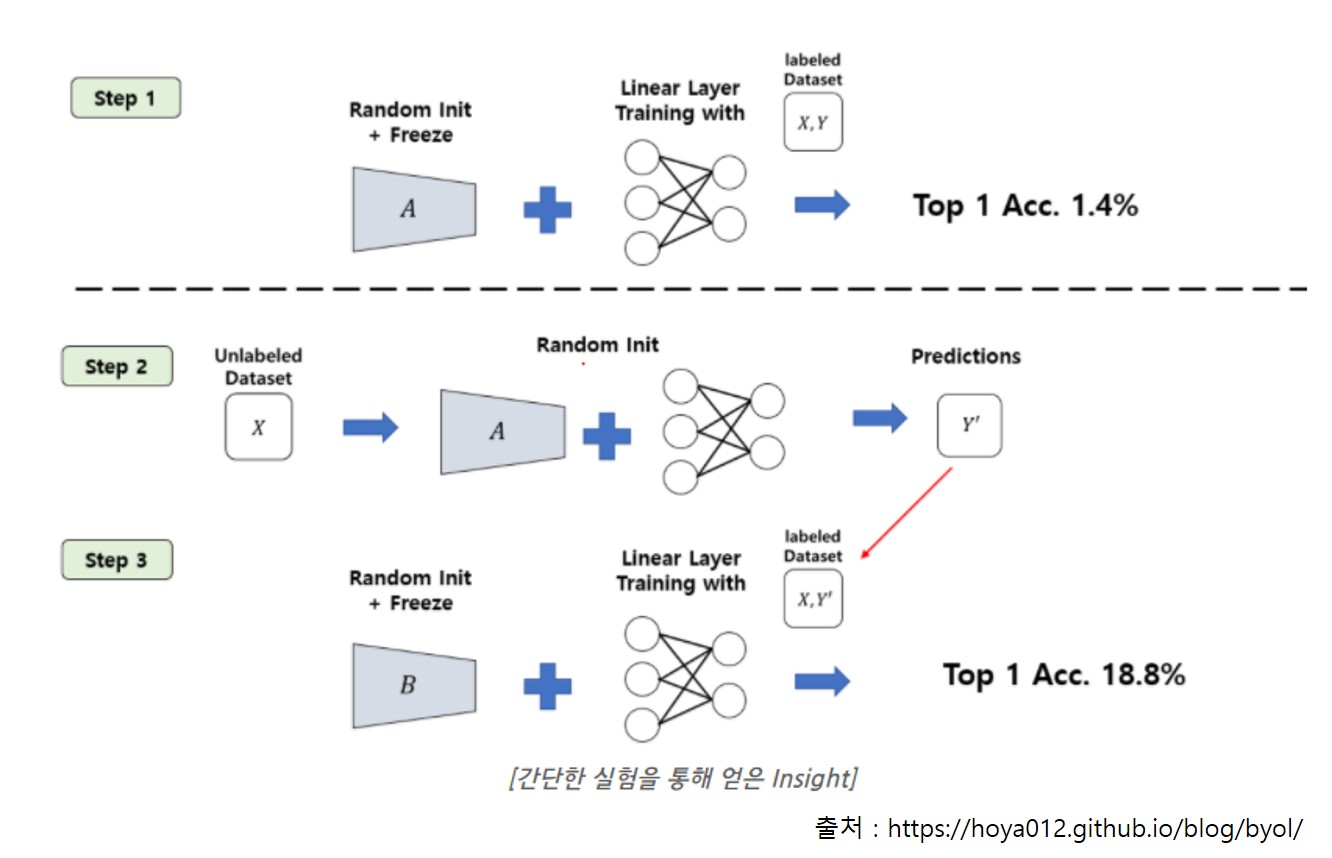
- step1 : randomly initialized network를 freeze하고 linear evaluation을 진행합니다.
-> Acc 1.4% - step2 : step1의 network에 MLP를 붙여 prediction 값을 얻습니다.
- step3 : step2에서 얻은 prediction 값을 target으로 하여 step1처럼 randomly initialized network를 학습하고 linear evaluation을 진행합니다.
-> Acc 18.8%
“동일 instance에 대해 다른 augmentation을 적용한 이미지는 representation이 동일해야 한다.” 가 instance discrimination 방식인 contrastive learning의 기본 아이디어 였는데요. 이 아이디어만으로 학습 framework을 구성할 시, 모델은 input과 무관하게 동일 representation을 출력하도록 학습될 수 있고 이를 논문에서는 ‘collapsed representations’이라고 말합니다. 이 문제가 이전 연구들에서 negative sample을 사용해야만 했던 이유라고 할 수 있습니다.
여기서, 학습을 시작하기전 randomly initialized network에서 얻은 representation을 생각해보면 이미지의 특성을 잘 반영한 representation은 아니겠지만, 아직 학습을 시작하지 않았기에 collapsed 문제는 없을 것으로 생각할 수 있습니다. 이렇게 얻은 representation의 성능이 step1에서 구한 1.4%였습니다. ImageNet 데이터가 1000개의 class임을 감안하면 학습한 1개의 linear layer에서 어느정도의 학습은 이루어진 것으로 보입니다.
step2~3의 결과는 step1에서 얻은 의미없는(randomly initilized 이므로) representation을 target으로 학습하는 것도 어느 정도의 의미는 있다는 것을 보여줍니다. 이 부분이 개인적으로 좀 신기한 부분이었는데요. 틀린 답으로 학습하는 것도 전혀 학습하지 않은 것보다는 도움이 된다고 해석할 수 있기 때문입니다.
논문에선 위 실험결과를 시작으로 representation을 학습할 online network와 학습하는 prediction을 출력할 target network를 아래와 같이 설계하게 됩니다.
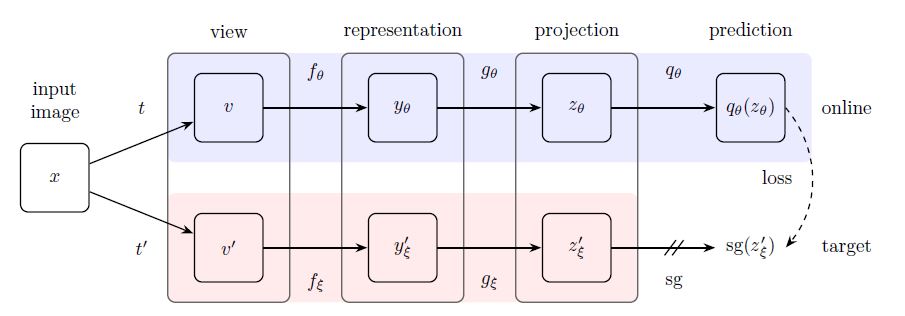
- $v, v’ : $ augmented image
- $f_{\theta}, f_{\xi} : $ randomly initialized network
- $g_{\theta}, g_{\xi} : $ projector
- $q_{\theta} : $ predictor
- $sg(z’_{\xi}) : $ stop gradient
서로 다른 augmentation을 적용한 이미지의 feature를 각각 계산하여 loss를 구하고 downstream task에는 $y_{\theta}$만 사용되는 점은 SimCLR와 유사한 형태이고, online과 target network가 구분된다는 점, online에만 predictor가 추가적으로 사용한 점이 큰 차이라고 볼 수 있습니다.
target network의 output은 stop gradient를 적용하고 loss를 계산하기에 online network만 학습 과정 중 직접적으로 학습되고, target network는 online network의 exponential moving average로 매 epoch 마다 업데이트 됩니다. 이 부분은 MoCo에서 사용한 momentum encoder와 유사해 보입니다.
@@\xi \leftarrow \tau \xi + (1-\tau)\theta @@
Loss와 전체 학습 알고리즘은 아래와 같은 모양이고, loss에 사용되는 $ q_{\theta}(z_{\theta}), z’_{\xi} $는 l2 normalization되어 사용됩니다. 그리고 online과 target network가 비대칭적인 구조이기에 augmentation을 바꿔서 적용한 loss도 더하여 최종 loss가 계산됩니다.
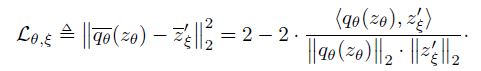

사용된 augmentation, architecture, optimization 방식은 대부분 SimCLR과 비슷하다고 하고, 논문 Appendix에 자세히 정리되어 있습니다.
Augmentation
- random patch, resize, random horizontal flip
- color distortion
- Gaussian blur, solarization
Architecture
- ResNet(layer:50,101,152,200, width:1x~4x)
- projector, predictor : MLP(4096, BN, ReLU, 256), 두 번째 layer 뒤에 BN이 사용되지 않은 점이 SimCLR과 다름
Optimization
- LARS optimizer, cosine decay lr schedule, 1000 epochs
- $\tau_{base}=0.996 $
- $\tau \triangleq 1-\left(1-\tau_{\text {base }}\right) \cdot(\cos (\pi k / K)+1) / 2$
- ResNet50 : batch size=4096, 512 Clout TPU v3 cores, 8 hours
Results
아래 ImageNet 데이터에 대한 Image representation 성능 측정에는 Unsupervised Learning 성능 측정에 표준으로 사용되는 Linear evaluation이 사용되었습니다.
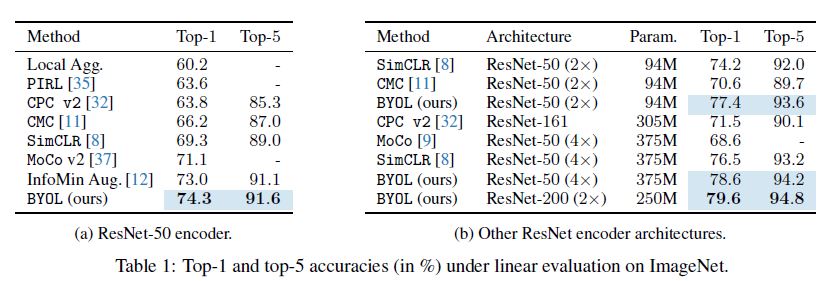
negative sample을 사용하지 않았음에도 BYOL을 ResNet50을 사용했을 때와 더 깊은 ResNet 계열 encoder을 사용했을 때 모두 이전 결과보다 우수한 성능을 보였습니다.
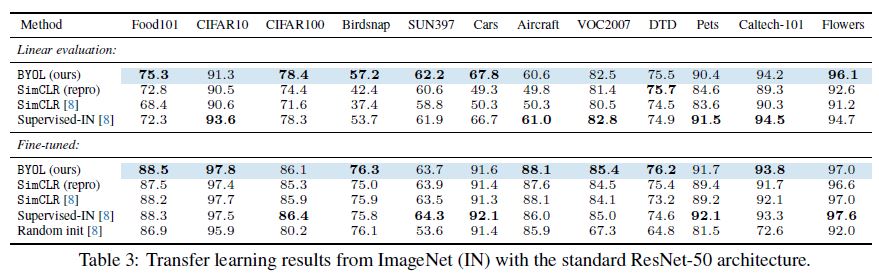
다양한 데이터에 대한 transfer learning 실험도 진행하였는데, 이 결과가 비교적 고무적인 것이 과반수 이상의 dataset에 대해 Supervised-IN 결과보다 우수했다는 점입니다.
MoCo에서도 segmentation, detection task에 대해선 representation을 학습한 모델이 ImageNet pretraind model 대비 transfer learning 성능이 우수함은 보여주었지만, classification task에서 ImageNet pretrained model을 뛰어넘기는 좀 더 어려운 과제였습니다. 위 결과에서도 SimCLR의 성능이 대부분의 dataset에서 Supervised-IN보다 떨어지는 것을 볼 수 있습니다.
하지만, BYOL에서는 절반 이상의 dataset에서 Supervised-IN보다 더 나은 결과를 보여주었고, 이는 random init 보다 더 나은 성능을 얻기 위해 pretrained model을 사용할 때 꼭 Label이 필요하지 않다는 의미입니다.
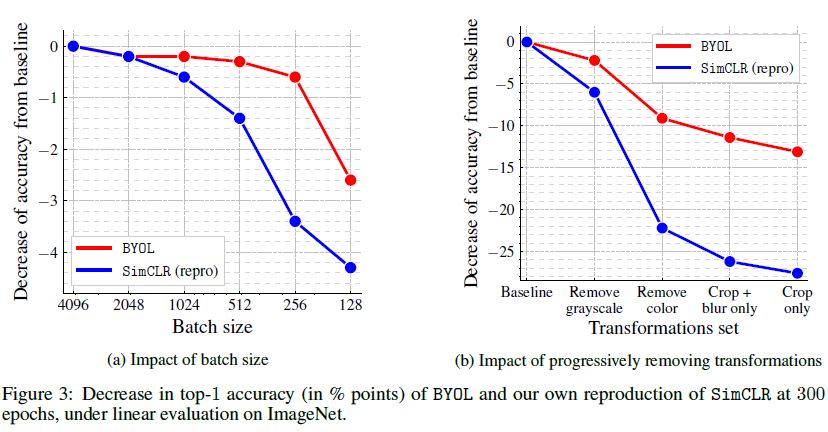
다음은 batch size와 augmentation에 대한 실험입니다.
위 그래프는 batch size를 4096부터 줄여가면서, 사용한 augmentation을 하나씩 줄이면서 baseline 대비 acc 하락을 보여주고 있습니다. SimCLR는 논문에서도 실험결과로 보여주었듯 batch size가 줄어들수록 많은 negative sample을 학습하지 못해서 성능하락이 뚜렷하고 augmentation 종류에도 성능이 민감함을 보여줍니다. BYOL은 SimCLR 대비 이러한 성능 하락 폭이 작아서 좀 더 robustness하다고 합니다.
또한, 두 그래프를 보면 batch size보단 augmentation이 성능에 좀 더 중요하고 SimCLR에서 설명했던 것처럼 color에 대한 augmentation이 특히 중요하다는 것이 확인 됩니다.
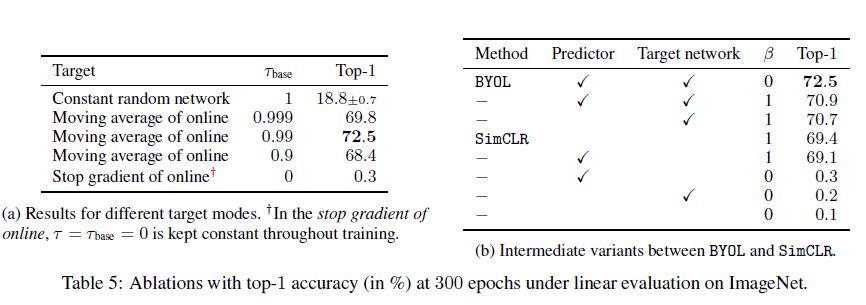
MoCo에서 momentum 값에 대한 실험을 했던 것처럼 BYOL에서도 target network을 업데이트하는 데 사용되는 $\tau_{base}$에 대한 실험을 진행 했는데 위 결과의 왼쪽은 이 결과를 보여줍니다. 1은 random init을 target network으로 사용하는 것을 말하고(motivation이 되었던 실험) 0은 online과 동일하게 설정하고 학습동안 stop gradient한 실험입니다. MoCo의 momentum 실험 결과과 유사하게 $\tau_{base}$가 0에 거의 근접한 값일 때 성능이 좋았고 이는 target network는 online보다 매우 천천히 학습되는 설정으로 해석할 수 있습니다.
오른쪽은 SimCLR에서는 없는 predictor와 target network, BYOL에서는 없는 negative sample의 효과에 대한 실험결과 입니다. $\beta$는 negative sample 유무를 의미합니다. predictor와 target network중 하나만 빠져도(6,7번째 줄 결과) 성능 하락이 심하고 둘을 같이 사용하면 negative sample을 사용하지 않아도 가장 좋은 성능을 보이기에 predictor와 target network의 시너지를 보여주는 결과인 것 같습니다.
Conclusion
논문의 표현인 아래 한 문장으로 이 논문을 요약할 수 있을 것 같습니다.
“BYOL learns its representation by predicting previous versions of its outputs, without using negative pairs.”
아직 덜 학습된 prediction을 target으로 학습하는 것으로 이미지의 representation을 학습할 수 있다는 점이 개인적으로 굉장히 신기했던 논문이지만, augmentation에 대한 민감도가 높다는 점은 논문에서도 한계로 지적하고 있습니다. 이미지 외 분야에서 BYOL을 활용하려면 적절한 augmentation을 찾는 데 많은 노력이 들 것이고 이를 자동화하는 연구가 BYOL을 generalize할 수 있을 것이라고 말하고 있습니다.
Reference
paper :
Bootstrap Your Own Latent A New Approach to Self-Supervised Learning
etc :
HOYA012’S RESEARCH BLOG : Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning 리뷰
https://2-chae.github.io/category/2.papers/26
https://cool24151.tistory.com/85
딥러닝논문읽기모임 : 조용민 - Bootstrap Your Own Latent(BYOL)