논문 리뷰 : Momentum Contrast for Unsupervised Visual Representation Learning
이 논문은 Facebook AI에서 발표하였고, 이미지 Representation Learning 분야에서 SimCLR과 라이벌 격인 논문입니다. SimCLR처럼 Contrastive Learning을 사용하였으며 momentum encoder를 사용하는 부분이 가장 큰 차이라고 할 수 있을 것 같습니다.
Intro
NLP에서는 GPT, BERT에서 보여주었듯이 Unsupervised Learning이 탁월한 성과를 보여주었지만, Computer vision 분야에서는 여전히 Supervised Learning으로 pre-trained 된 모델의 성능이 우세했습니다. 언어는 특정 words로 구성되기에 discrete한 영역안에 있고, 언어모델은 단어사전과 같은 unsupervised learning 기반에서 시작하기에 이미지보다 representation을 학습하기 쉽다는 이유인데요. MoCo에서는 Computer vision 분야에서 representation을 학습한 모델이 다양한 데이터에 대해 segmentation, detection을 수행하는 7가지 downstream task에서 ImageNet pretrained 모델 대비 우수한 성능을 달성 하였습니다. 최근 이미지 representation 학습에서 뛰어난 성과를 보여준 contrastive learning과 dynamic dictionary를 활용하였다고 하는데, 각각에 대해 자세히 살펴보겠습니다.
Methode
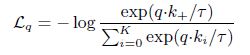
- $L_{q}$ : query 하나에 대한 loss
- $\tau$ : temperature, hyper parameter
사용된 loss는 위와 같은 모양입니다.
distanace로는 dot product가 사용되었고, sample 하나 당 1개의 positive sample과는 가깝게, K개의 negative sample과는 멀게하는 InfoNCE가 사용되었습니다.
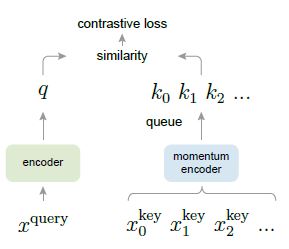
위 그림에서 queue가 dictionary를 의미하며, batch size보다 dictionary size를 크게하는 것이 학습 시 좀 더 많은 negative sample을 볼 수 있게 합니다. input 이미지가 momentum encoder를 통과한 key값이 queue를 구성하게 되는데, 그림의 구조가 batch마다 반복되는 것은 아니고, 한 번 queue에 저장된 key값은 추가되는 key값이 dictionary size를 초과하지 않는 한 유지되는 형태입니다.
학습 과정은 논문의 Algorithm 1을 보면 좀 더 정확히 알 수 있습니다.

- #1 : momentum encoder를 encoder로 initialize 합니다.
- #3~4 : augmented 이미지로 query와 key에 해당하는 이미지를 정의합니다. augmentation에는 reisze and crop, color jittering, random horizontal flip, random grayscale conversion이 사용되었습니다.
- #5~7 : #3~4에서 구분된 input이 각각 encoder와 momentum encoder를 통과하고 momentum encoder에 대해서는 gradient가 계산되지 않도록 합니다.(backpropagation 제외)
- #9~12 : positive, negative 각각에 대해 logit을 계산하고 InfoNCE를 계산합니다.
- #13~15 : backpropagation하여 encoder를 update하고 기존에 대한 momentum m을 가지도록 momentum encoder를 재정의 합니다.
- #16~17 queue에 이번 minibatch의 key(feature)를 추가하고 가장 오래된 key값을 제외합니다.
논문에선 이 알고리즘이 기존과 어떻게 다른지에 대해서도 아래 그림을 통해 설명하고 있습니다.
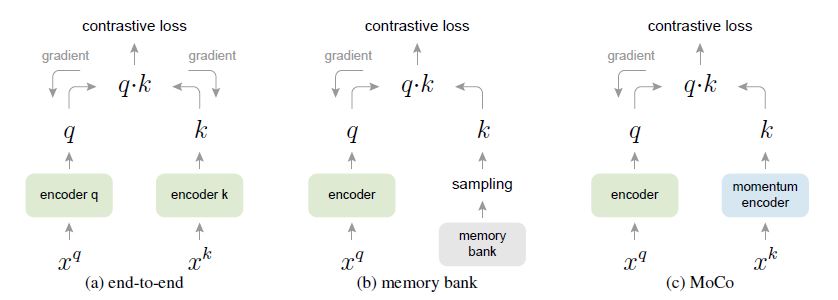
먼저, (a)는 dictionary를 따로 구성하지않고 end-to-end로 학습하는 방법으로 query와 key가 같은 encoder를 통과한다고 생각하면 이전에 리뷰했던 SimCLR 형태와 같습니다. 이 경우 negative sample을 많이 보기 위해선 batch size를 크게 해야 하는데요. 실제로 SimCLR에서는 batch size를 8192까지 사용했습니다.(default 는 4192였습니다.)
(b)는 이미지의 key값을 미리 memory bank에 저장해두는 방식입니다. batch size를 크게 하지 않아도 memory bank에 저장된 많은 negative sample의 key값을 사용할 수 있다는 장점이 있는 반면, encoder가 업데이트 됨에 따라 미리 저장된 key값이 consistent하지 않다는 문제가 있습니다.
(a), (b)의 문제들을 모두 해결한 방식이 (c)MoCo의 형태로 momentum encoder를 사용해 encoder와 dictionary key를 cosistent하게 유지하면서 batch size에 상관없이 많은 negative sample을 볼 수 있게 되었습니다.
Results
위 (a), (b), (c) 각각의 구조에 대해 Linear Classification protocol로 비교한 결과 입니다. Linear Classification protocol은 학습된 모델은 freeze하고 linear layer 하나만 추가해서 supervised learing으로 학습하여 평가하는 방식을 말합니다.(SimCLR에서 사용한 방법과 같습니다.)
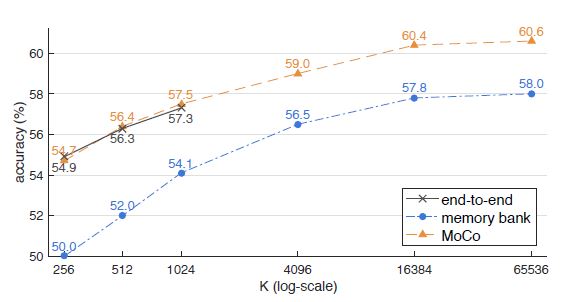
memory bank 방식이 성능이 떨어졌고, end-to-end와 MoCo는 비슷한 수준의 성능을 보였습니다. 하지만 dictionary size는 크게할 수 있지만 batch size를 크게하는 데에는 memory의 제약이 있다는 점에서 MoCO의 장점을 말하고 있습니다. 많은 negative sample을 볼수록 성능이 좋은데, MoCo의 구조가 end-to-end 대비 negative sample을 많이 보게하는 데 유리하다는 것입니다.
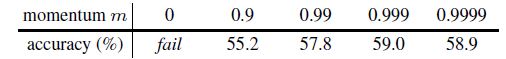
다음은, momentum encoder를 정의하는 momentum m 값에 따른 실험 결과 입니다.
0.99~0.9999에서 최대값을 가지고 0.9에서는 성능이 확연히 떨어지는 것으로 보아 momentum encoder는 encoder 대비 훨씬 느리게 update하는 것이 좋다고 합니다.
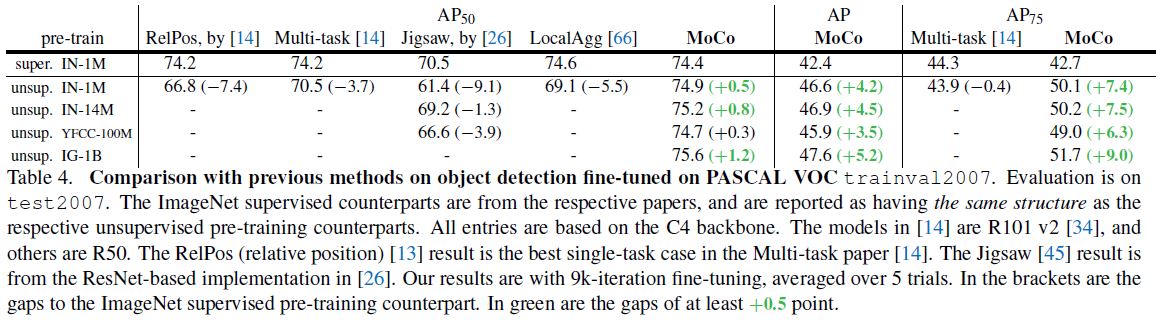 MoCo는 object detection, segmentation에서 ImageNet pretrained 모델을 사용했을 때보다 높은 성능을 보였습니다.
MoCo는 object detection, segmentation에서 ImageNet pretrained 모델을 사용했을 때보다 높은 성능을 보였습니다.
이는 어떤 task에 대해 더 나은 성능을 위한 pre-training 과정에서 Label이 필요하지 않다는 것이므로 상당히 의미있는 결과이지 않나 생각합니다.
이 논문에서 제시한 다른 논문과의 성능 비교에선 SimCLR에 빠져 있어서(아마도 SimCLR보다 먼저 발표된 논문 같습니다.), SimCLR에서 제시한 결과 상에서 MoCo를 확인해 보았습니다.
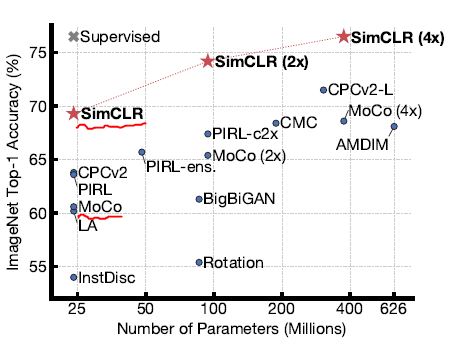
ResNet50의 결과를 보면 MoCo의 결과는 SimCLR 뿐 아니라 CPCv2 등 다른 결과보다도 좋지 않음을 확인할 수 있습니다.
사실, SimCLR 에서 적용한 것처럼 큰 batch size를 사용하지 않아도 된다는 점만으로도 충분히 의미가 있어 보이지만, Facebook AI 팀에선 다른 연구들에서 사용했던 방법들을 적용하여 기존 MoCo를 tuning한 MoCo_v2를 발표하였습니다.
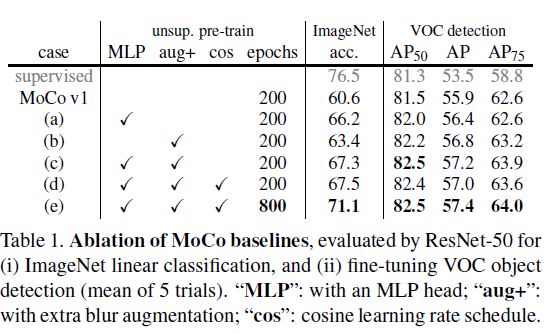
위 결과를 보면 MoCo v1에서는 VOC detection에서 ImageNet pre-training 이상의 성능을 보였지만 ImageNet acc에서 성능이 많이 떨어졌는데요, 여기서 아래 4가지 방법을 사용하여 성능이 얼마나 개선되었는지를 볼 수 있습니다.
- MLP (2개의 linear layer, ReLu)
- blur augmentation
- cosine lr schedule
- training epoch 증가
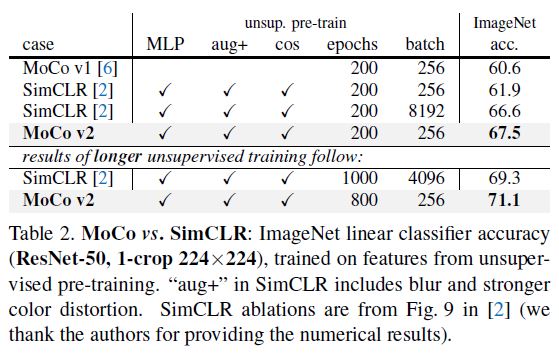
이러한 tuning 과정을 거치고 난 MoCo v2는 SimCLR처럼 큰 batch를 사용하지 않아도 ImageNet acc에서 더 높은 결과를 보여주고 있습니다.
Conclusion
MoCo에선 dictionary를 사용하여 batch size에 상관없이 negative sample을 많이 볼 수 있게 하면서도 기존 memory bank의 문제점 역시 momentum encoder를 사용하는 것으로 해결할 수 있음을 보여주었습니다. 하지만 pretext task는 instance discrimination 기반의 기존 방법을 그대로 사용하였기에 이 부분에서 활용 및 개선될 여지가 있다고 합니다.
Reference
paper :
Momentum Contrast for Unsupervised Visual Representation Learning
Improved Baselines with Momentum Contrastive Learning
etc :
PR-260: Momentum Contrast for Unsupervised Visual Representation Learning
투빅스 생성모델 세미나 : Self-Supervised Learning
https://cool24151.tistory.com/82