논문 리뷰 : A Simple Framework for Contrastive Learning of Visual Representations
이 논문은 Google Brain에서 낸 논문으로, Geoffrey Hinton 교수님이 교신저자로 참여하신 논문인데요, 학습과정에서 augmentation과의 차이를 학습하는 것으로 image representation 성능을 크게 향상 시킨 논문입니다.
Intro
이 논문에선 contrastive self-supervised learning을 제안하였는데, 이 구조는 복잡하지 않으며 별도의 memory bank가 필요하지 않다는 데에서 이전 연구들과 차이가 있습니다. 논문에서 입증한 바는 크게 3가지 입니다.
- data augmentation 조합이 SimCLR 구조에서 중요한 역할을 한다.
- representation과 contrasitve loss 사이의 non-linear transformation이 representation 성능을 향상시킨다.
- contrastive learning은 batch size와 training step이 클 때 효과적이다.
이미지에 대한 representation learning은 크게 generative와 discriminative로 나눠집니다. generative 접근방식은 말 그대로 이미지를 reproducing하는 과정에서 유의미한 representation을 학습하는 방식이고, discriminative는 pretext를 정의하고 이에 맞는 objective function을 정의하는 방식입니다.
이 논문에선 discriminative 방법 중 하나인 contrastive learning을 사용하였고, 다양한 실험을 통해 효율적으로 representation을 학습할 수 있는 구조를 제안하고 있습니다.
Framework
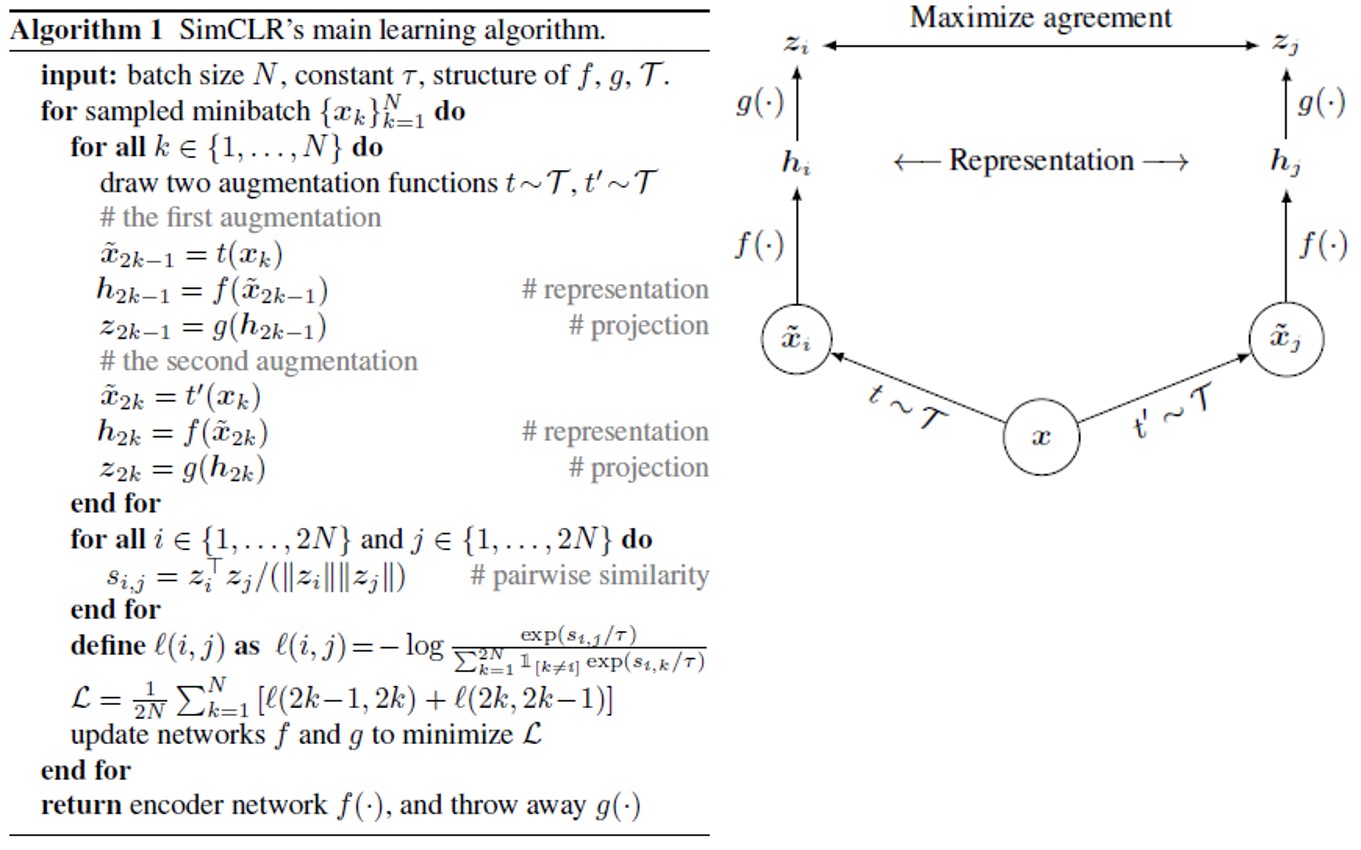 학습 알고리즘과 contrastive learning은 위 그림으로 모두 설명할 수 있습니다.
학습 알고리즘과 contrastive learning은 위 그림으로 모두 설명할 수 있습니다.
- $\mathcal{T}$ : 사용될 augmenation의 종류
- $t, t^{‘}$ : $\mathcal{T}$에서 random sampling된 augmentation
- $\widetilde{x}_i, \widetilde{x}_j$ : augmenation된 이미지
- $f(\cdot)$ : resnet50 output에서 global average pooling된 값, 2048-dimension
- $g(\cdot)$ : projection head로 두 층의 MLP와 activation 함수 relu가 사용됨, contrastive loss와 representation 사이의 non-linear representation이 적용되었다고 한 부분
- ImageNet ILSVRC-2012 dataset 사용
- Linear evaluation protocol으로 evaluation : representation까지의 parameter를 freeze하고 linear layer 하나만 추가하여 supervised learning, evaluation 진행
그럼 loss 식의 구성을 하나씩 살펴보겠습니다.
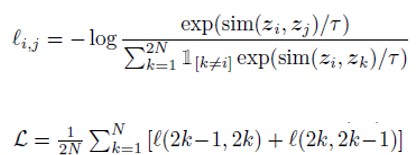
- similarity : cosine similarity
- $\tau$ : temperature scaling parameter
- i, j : 같은 이미지에 대해 다른 augmentation을 적용한 두 이미지
- N : batch size
첫 번째 식을 보면 i와 j의 순서에 따라 loss값이 달라지는 것을 알 수 있는데, 이 때문에 두 번째 식 처럼 순서를 바꾼 두 loss 값을 더해주고 분모에 2를 추가해주는 형태가 됩니다.
아래 그림을 보면 위 loss 식을 직관적으로 이해할 수 있습니다.

고양이와 코끼리 이미지 하나씩으로 구성된 batch_size=2의 batch를 가정해봅시다.
i, j가 augmentation된 고양이 이미지라고 하면 위 그림과 같이 분모는 i와 다른 이미지들의 similarity 합이 되고, 분자는 i와 j 사이의 similarity가 됩니다.
즉, 같은 이미지에 대한 다른 augmentation은 positive sample, 다른 이미지에 대한 augmentation 이미지는 모두 negative sample로 분류하여
positive sample과의 similarity는 크게, negative sample과의 similarity는 작게 학습하기 위한 loss 함수로 생각할 수 있습니다.
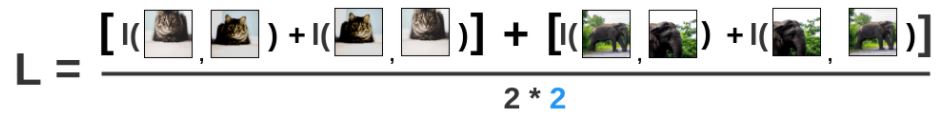
그리고 전체 batch에 대한 loss를 구해보면 위 그림과 같이 분자에는 페어 순서에 따라 다른 loss값들을 모두 더해주고 분모는 batch_size * 2가 오게됩니다.
논문에선 batch_size를 256~8192까지 다양하게 실험을 하였다고 하는데, 8192개의 batch로 가정하면 이미지 하나당 분모에 더해지는 negative sample과의 similarity는 2*(8192-1) = 16382가 됩니다. 이렇게 큰 batch_size를 적용하기 위해 TPU core를 32~128개까지 사용했다고 하는데, Google의 자원력을 확인할 수 있는 부분인 것 같습니다.
Augmentation
논문에서 사용한 augmentation 종류는 random crop(with flip and resize), color distortion, Gaussian blur 인데요, 이러한 augmentation을 사용하는 것으로 이전까지 연구들에서 적용한 architecture의 변화를 대체했다고 합니다. 그리고 이러한 augmentation을 적용하기까지 실험적인 결과들이 있었는데요.
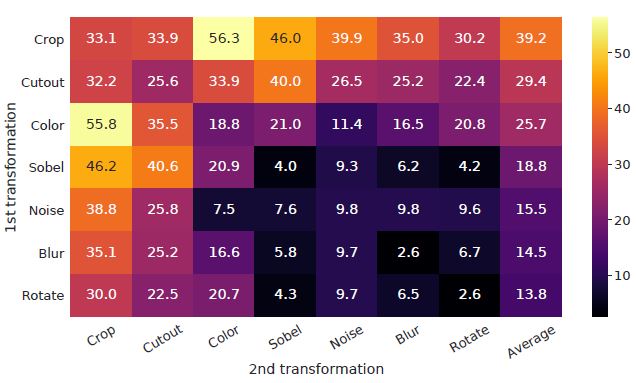
위 matrix는 SimCLR Framework로 학습하고 Linear evaluation 방식으로 evaluation한 결과입니다. 위에서 설명한 framework에서 서로 다른 augmentation 두 개로 이미지를 생성했던 것과 달리, 이 실험에선 한 쪽 branch는 원본 이미지 그대로 사용하고, 다른 한쪽의 branch에서 위 matrix 각각에 해당하는 augmentation을 사용했습니다.
행과 열이 같은 부분에선 augmentation 하나만 사용한 것이고 다른 성분에 대해선 그림에 명시한대로 행, 열 순으로 sequential하게 두 개의 augmentation을 모두 사용한 것입니다.
물론, ImageNet data는 사이즈가 일정하지 않기 때문에 전체 이미지에 대해서 crop, resize하는 과정이 선행으로 적용됩니다.
matrix 중 눈에 띄는 성능을 보인 augmentation 조합이 crop과 color 입니다.
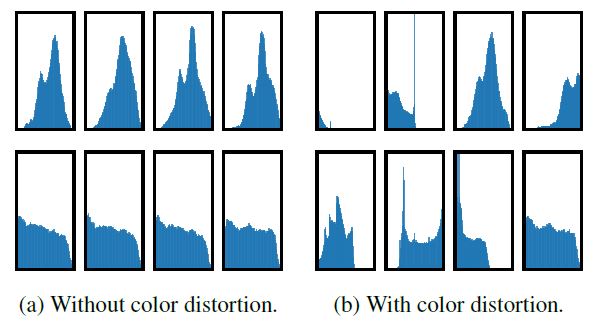
위 히스토그램은 다른 두 이미지에 대한 crop 이미지의 pixel 히스토그램입니다.
(a)그래프를 보면 같은 이미지에 대한 crop 이미지는 히스토그램이 거의 유사하고, 이는 이런 픽셀분포만으로도 다른 이미지를 구분할 수 있다는 의미가 됩니다.
즉, color distortion 없이 단순 crop만으로는 유의미한 representation이 학습되기 어렵고, 두 가지를 같이 사용해야 representation이 잘 학습될 수 있게 되는 것입니다.
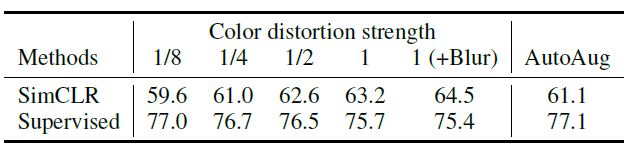
또한, contrastive learning을 적용할 땐, supervised learning과 달리 augmentation의 강도를 크게 했을 때 더 효과적이었는데요.
위 표를보면 supervised learning의 경우 color distortion을 강하게 적용해도 성능향상이 없거나 오히려 성능이 하락했지만 SimCLR에선 AutoAug같은 정교한 방법을 사용하지 않고 단순히
단순히 color distortion strength를 높이고 blur를 추가했을 때 가장 좋은 성능을 보였습니다.
Architecture
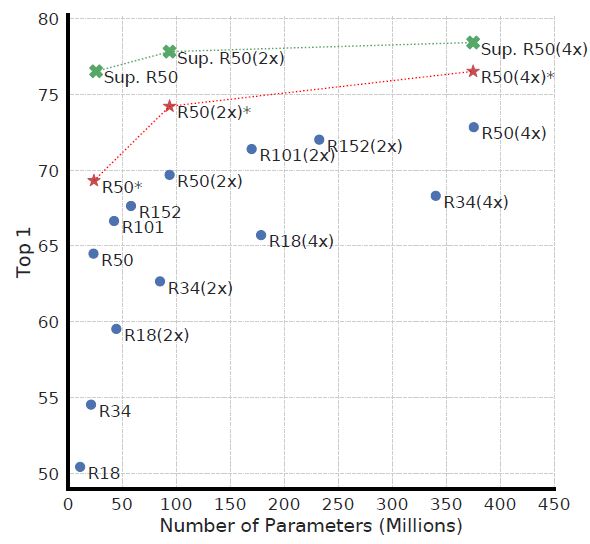
- blue : SimCLR model로 100 epoch 학습 후 Linear evaluation
- red : SimCLR model로 1000 epoch 학습 후 Linear evaluation
- grean : Supervised Learning
이 결과가 논문에서 제시한 SimCLR의 전체적인 성능입니다.
SimCLR의 성능은 ResNet50x4 사용 시 supervised learning으로 학습한 ResNet50과 비슷한 수준입니다. 이 결과가 이전 sota 대비 7% 이상 개선된 것이라고 합니다.
또한, 위 그래프를 통해 SimCLR의 학습 시, 모델 depth&width를 크게하고 학습을 오래할 수록 supervised learning 대비 성능 향상 폭이 큼을 확인할 수 있습니다.
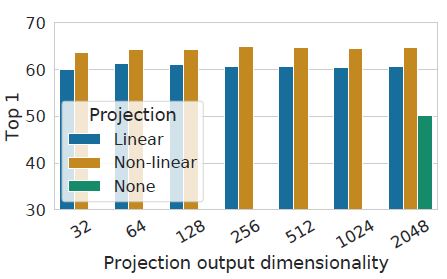
위 그래프는 projection head 부분에 사용한 non-linear transformation의 성능을 보여줍니다.
MLP layer 하나만 사용한 Linear과 representation을 그대로 사용한 None 대비 2개의 MLP layer와 relu를 사용한 non-linear transfomation 적용시 성능이 가장 좋았습니다.
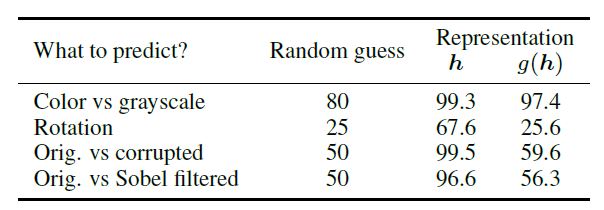
개인적으론 위 결과가 좀 흥미로운 결과이지 않나 생각합니다.
논문을 보면서 든 의문이, representation에 추가한 transformation의 output으로 constrastive loss를 계산하고 Linear evaluation 시에는 representation을 사용하는 부분에 있었습니다.
loss 자체는 같은 이미지에서 augmentation된 이미지들의 similarity를 높게하는 term이기에 결국, f와 g는 이미지의 유의미한 representation뿐 아니라 적용된 augmentation에 둔감해지는 방향으로 학습되게 될 것입니다. 여기서 f의 output을 representation으로 사용한다는 것은 이미지의 유의미한 representation은 f에서 학습되고, g는 augmentation으로 인한 변화를 무시(?)하도록 학습됨을 ‘가정’하는 것 같습니다.
하지만, 위 결과를 보면 g(h)를 representation으로 사용했을 때, 이미지 변환에 대한 인식률이 떨어졌고 이는 ‘가정’이 어느정도 맞다고 보여집니다.
이 결과는 아마도, convolution filter로 학습한 이미지의 feature가 augmentation된 이미지를 더 잘 구분할 수 있기 때문인 것 같습니다. 이렇게 생각하면 rotation에 대해 g(h)를 representation으로 사용했을 때의 성능이 현저히 떨어지는 것이 이해가 되는 것 같습니다.
Loss functions and Batch Size
positive, negative sample을 활용한 학습은 이전에도 있었고, 다른 loss함수들도 존재하기에 논문에선 이들과 비교한 실험결과도 공유하고 있습니다.

contrastive loss(NT-Xent) 외에 위 두 개의 loss를 사용하였고, NT-Logistic과 Margin Triplet은 negative sample에 대해 따로 가중치를 주지 않기에 이 loss에 대해서는semi-hard negative mining 방법도 추가적으로 실험하였습니다.
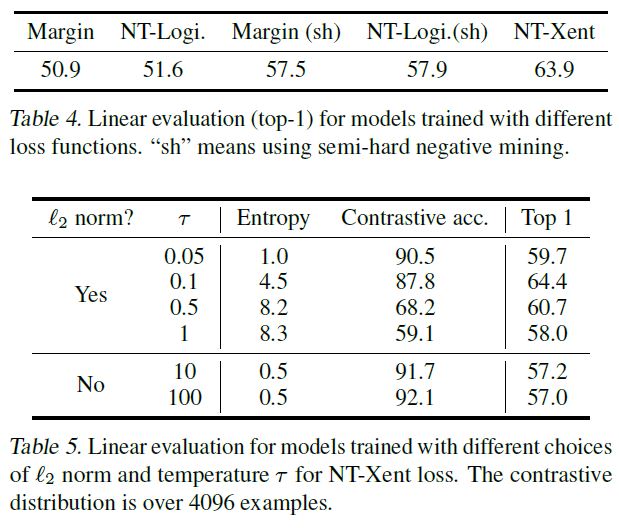
위 결과에서 이들 중 NT-Xent(Normalized Temperature-scaled Cross Entropy)의 성능이 가장 좋음을 보여줍니다.
Comparison with other State-of-the-art
이전의 다른 State-of-the-art 결과들과의 비교 결과도 있습니다.
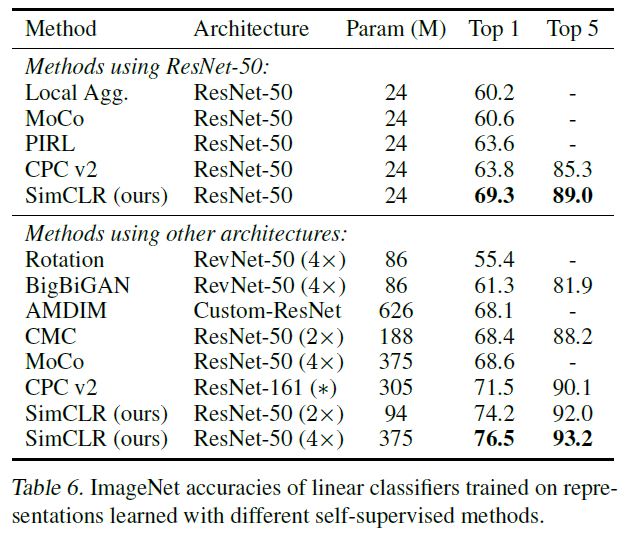
Linear evaluation 결과를 비교하였을 때, Architecture별로 ResNet50을 사용한 결과와 더 깊은 구조를 사용했을 때의 결과 모두 SimCLR에서 가장 뛰어났습니다. 이외에도 transfer learning, semi-supervsied learning에 대한 실험에서도 우수한 성능을 보였는데, 이 부분들에 대해 궁금하신 분은 논문을 참조하시면 좋을 것 같습니다.
Conclusion
- Simple framework로 self-supervised learning, semi-supervised learning, transfer learning의 성능을 크게 개선하였다.
- supervised learning과는 다른 augmentation과 non-linear porjection head를 제안하였다.
- representation을 학습하는 것으로 supervised learning 수준의 성능을 달성하였다.
Reference
paper :
SimCLR : https://arxiv.org/abs/2002.05709
etc :
The Illustrated SimCLR Framework : https://amitness.com/2020/03/illustrated-simclr/
PR-231 : https://www.youtube.com/watch?v=FWhM3juUM6s&t=1s
https://creamnuts.github.io/paper/simCLR/