Data Efficient Learning
이번 포스트에선 Data Efficient Learning 관련 연구 몇 가지를 정리해보았습니다.
Prototypical Networks for Few shot Learning
Overview
기존에 학습 데이터에 없었던 새로운 데이터를 few-shot으로 분류하는 few-shot classification task를 수행하는 연구입니다. 이 논문에선 새로운 데이터를 기존 학습 데이터와 합쳐서 처음부터 학습하는 방식이 아닌 prototype을 활용한 metric learning 방식을 제안합니다.
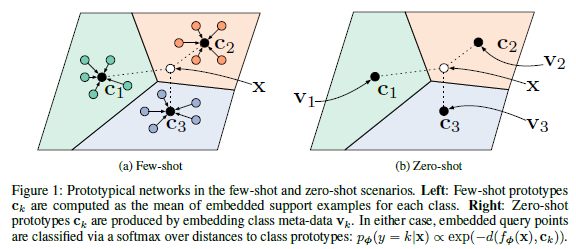
Neural net을 mapping 함수로 사용하며 few-shot의 경우 embedding 공간안에서 prototype \mathbf{c}_k를 계산하고 zero-shot의 경우 기존에 존재하는 prototype 중 가장 가까운 class로 분류합니다. 이러한 방식을 통해 논문에선 학습데이터의 추가 시나리오에 직관적이고 효율적인 학습 알고리즘을 제안하였다고 볼 수 있을 것 같습니다.
Method
제안된 Method는 크게 prototype을 계산하는 부분과 기존 prototype을 사용해 분류하는 과정으로 나눠집니다.
Prototype 계산
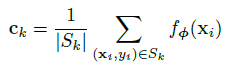
Class별 probability 계산
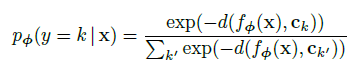
알고리즘은 K-means clustering의 centroid를 계산하고 membership을 할당하는 과정과 거의 똑같아 보입니다.

- 학습 데이터 샘플링
- Prototype을 계산하여 분류모델 생성
- query(학습에 추가할 데이터)에 대해 모든 prototype과의 거리를 계산하고 softmax를 사용해 classification score 계산
- query classification loss를 사용하여 모델 학습
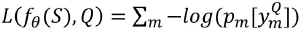
Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks
Overview
MAML은 few-shot classification을 parameter optimization 관점으로 접근한 Optimization based meta-learning의 대표적인 논문이라고 할 수 있습니다.
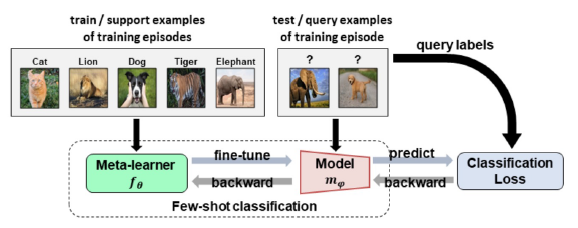
제안 방법은 데이터를 meta-trainset과 meta-testset으로 분리하여 meta-train으로 학습한 meta-learner를 meta-testset으로 fine tuning하였을 때의 성능을 maximize할 수 있도록 meta-learner를 학습하는 방식입니다.
Method

알고리즘을 보면 while-for의 이중 반복문이 사용된 것을 볼 수 있는데 각각은 outer loop와 inner loop 또는 task-specific 학습과 meta knowledge의 학습 등으로 구분할 수 있습니다. 전체 과정을 요약하면 다음과 같습니다.
- 학습 데이터 샘플링(meta trainset, meta testset)
-
Inner optimization
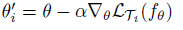
- Query(또는 meta testset)에 대한 prediction
- Outer optimization
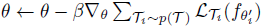
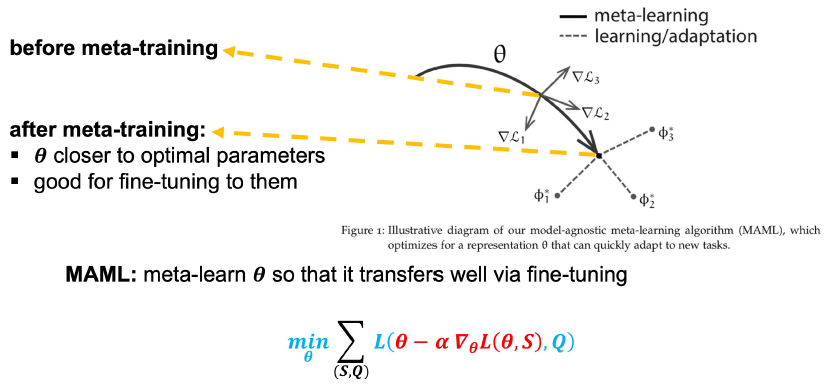
위 그림은 reference의 유튜브 강의자료에 있는 MAML에 대한 도식입니다. 그림에서도 명확히 드러나듯, MAML의 핵심은 task-specific한 fine-tuning을 잘하기 위한 meta-training 알고리즘을 제안한 것이라 할 수 있습니다. 이름에서 model-agnostic이라고 명명한 것처럼 어느 task, model에나 사용될 수 있다는 장점 때문에 MAML은 이 후 여러 연구들에서 활용되고 있지만, 이중 반복문을 사용하는 bi-level optimization 과정은 많은 연산량을 필요로한다는 단점도 존재합니다.
CyCADA: Cycle Consistent Adversarial Domain Adaptation
Overview

CyCADA에선 Image to image translation을 통해 domain adaptation을 수행했고, 원본 이미지를 target의 style로 효과적으로 변환하면서 기존 task를 잘 수행할 수 있는 Cycle consistent adversarial training 방식을 제안합니다.
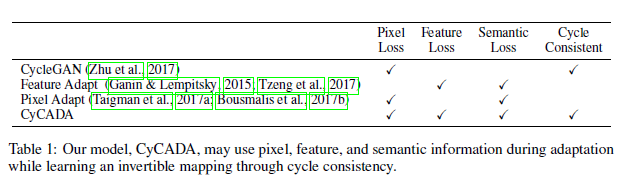
논문에서 사용한 Loss 는 크게 4가지로 위와 같이 이전 방법론 들에서 제안되었던 것들을 잘 조합하여 성능을 낸 연구입니다.
Method
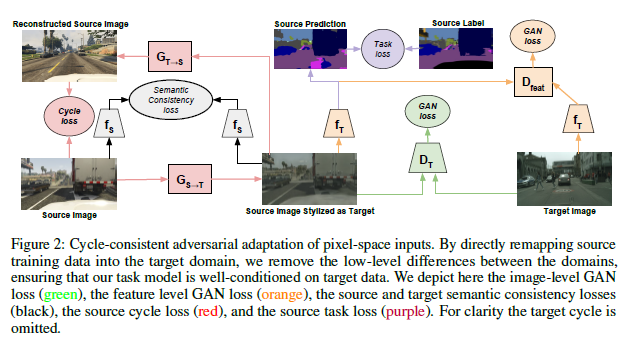
전체 framework은 위와 같고 제안된 Loss는 Pixel Loss, Feature Loss, Semantic Loss, Cycle Consistent로 4가지 입니다.
Pixel Loss
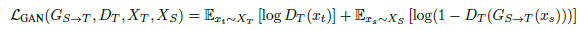 $S, T$ : Source, Target , $X$ : 이미지, $G_{S\rightarrow T}$ : Source에서 Target으로 translation하는 generator
$S, T$ : Source, Target , $X$ : 이미지, $G_{S\rightarrow T}$ : Source에서 Target으로 translation하는 generator
GAN loss(green) : 일반적인 GAN loss처럼 생성(혹은 translation)된 이미지와 실제(target) 이미지를 Discriminator는 구분하도록, Generator는 구분하지 못하도록 학습하게 하는 역할을 합니다.
Feature Loss
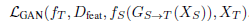
Gan loss(orange) : 일반적인 GAN loss를 feature level에서 수행합니다.
Semantic Loss
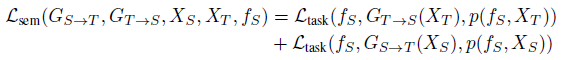
Semantic Consistency loss(black) : source 이미지와 source를 translation 한 후의 이미지가 동일한 task를 잘 수행하도록 일치 시켜주는 역할을 합니다. $f_S$는 task에 대해 사전학습된 모델이고, freeze 된 상태에서 나머지가 학습됩니다.
Cycle Consistent
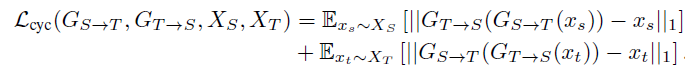
Cycle loss(red) : source-target-source 순으로 translate한 이미지가 잘 복원될 수 있도록 하는 loss로 CycleGAN에서 처음 제안되었습니다. 이 loss는 target으로 domain전환 후에도 source의 content는 잘 유지할 수 있게 합니다.
아래 예시를 보면, 3번째 이미지는 변환 후에도 ‘3’이라는 content를 잘 유지했고, 첫 번째와 두 번째 이미지는 숫자가 두 개 이상 존재해 그 중 하나를 유지한 것을 볼 수 있습니다.

Meta Pseudo Labels
Overview
Meta Pseudo Labels은 Semi-supervised setting에서 Image classification task의 SOTA를 달성했던 논문으로, Unlabeled data에 대해 pseudo label을 사용할 때 meta learning 방식이 사용됩니다.
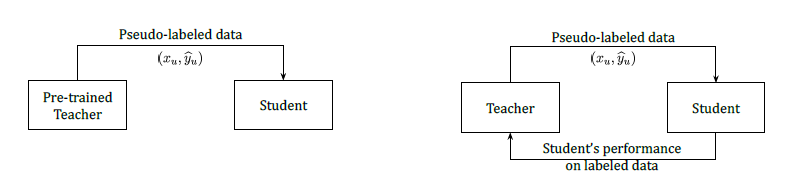
Pseudo label(left) : 사전학습된 고정된 teacher가 pseudo label을 생성하고 student모델이 이를 target으로 학습한다.
Meta Pseudo label(right) : Teacher는 unlabeled data로 pseudo label을 생성하고 이를 target으로 학습한 student가 labeled data에 대해 좋은 성능을 내도록 teacher가 다시 업데이트 된다.
Labeled data는 student 학습에 직접적으로 사용되지 않기 때문에 오버피팅 경향이 기존보다 적으며 제안방법으로 학습 후, labeled data를 사용해 fine-tuning하면 성능 향상이 조금 더 가능하다고 합니다.
MPL은 Teacher를 target으로 학습한 student로 부터 다시 teacher가 피드백을 받는 구조이기 때문에 teacher의 학습에는 그래디언트의 그래디언트가 사용됩니다. 이는 optimization based meta learning 방식에서도 문제가 되었던 Bi-level optimization problem을 야기하고, 이 부분을 그대로 다 계산하면 연산량이 너무 많아지게 됩니다. 논문에선 Hard pseudo label을 사용하는 약간의 트릭을 사용해 이 부분을 간단히 하고 있고 이에 대한 자세한 과정은 Appendix에 설명되어 있습니다.
Method
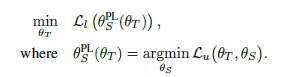
@@ T : \text{teacher},\,\, S : \text{student},\,\, l : \text{labeled}, \,\, u : \text{unlabeled} @@
objective function은 위와 같습니다. 과정은 teacher가 생성한 pseudo label로 student 모델을 먼저 학습하고(=$\theta_S^{\mathbf{PL}}(\theta_T)$), 이를 $\theta_T$에 대한 함수로 생각하여 labeled data를 사용해 Loss를 minimize하는 순으로 진행됩니다.
이를 좀 더 자세히 보면 아래 식과 같이 labeled, unlabeled batch를 하나씩 사용해 teacher, student의 update를 반복하는 형태로, MAML의 방식을 따르고 있습니다.
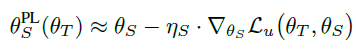
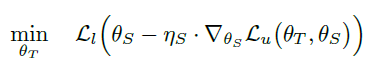
그럼 전체 Algorithm을 보겠습니다.

- Teacher가 생성한 pseudo label을 사용해 student를 update합니다.

- Teacher 학습을 위해 필요한 Bi-level optimization의 과정은 위와 같이 세 개의 cross-entropy loss의 gradient 곱을 사용하고 있습니다.(자세한 유도과정은 Appendix 참조)

- Teacher의 학습에는 다른 loss들도 같이 사용되며 논문에서 사용한 것은 위 두 가지 입니다. $g^{(t)}{T,supervised}$는 Labeled data를 직접 teacher 학습에 사용하는 supervised loss를 의미하고 $g^{(t)}{T,UDA}$는 RandAugment를 적용한 output이 non-augment와 같아지도록 하는 UDA(Unsupervised Data Augmentation) loss입니다.
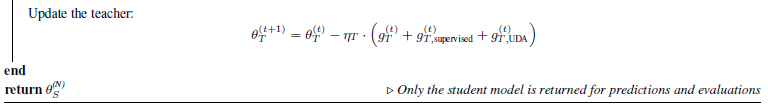
- 마지막으로 위와 같이 전체 gradient를 합쳐서 teacher의 parameter를 update합니다. 최종 prediction 및 evaluation에는 student가 사용됩니다.
Reference
paper :
Prototypical Networks for Few-shot Learning
Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks
CyCADA: Cycle Consistent Adversarial Domain Adaptation
Meta Pseudo Labels
other :
Lecture12 AAA738 SeungryongKim