Attention in Computer Vision
이번 포스트에선 Computer Vision에 Attention 또는 Transformer 구조가 사용된 몇 가지 논문에 대해 정리해 보았습니다.
Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
위는 2015년도에 나온 논문으로, ‘Attention is All You Need’를 통해 Transformer 형태의 Attention이 등장하기 이전에 Image Captioning task에 Attention의 개념을 사용했던 논문입니다.
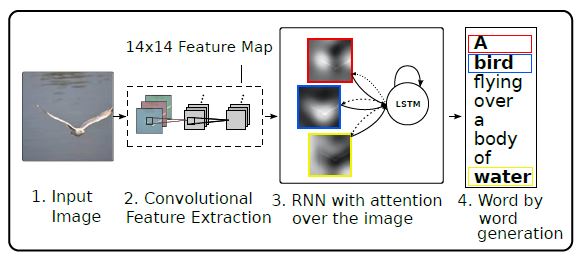
Image Captioning은 image를 입력으로 받아 이를 설명하는 문장을 생성하는 task를 말합니다. 모델은 위 그림과 같이 CNN과 RNN이 모두 사용되는 구조이고, CNN의 output feature map이 RNN을 거치면서 sequence를 구성하는 단어들을 생성하게 됩니다. 이 때, RNN 구조에 Attention을 적용한 것이 이 논문의 contribution이고 이를 통해 생성된 단어별 해당 영역을 아래와 같이 이미지에 표시할 수 있게 됩니다.

아래 그림을 보면 전체 프로세스를 쉽게 이해할 수 있습니다.
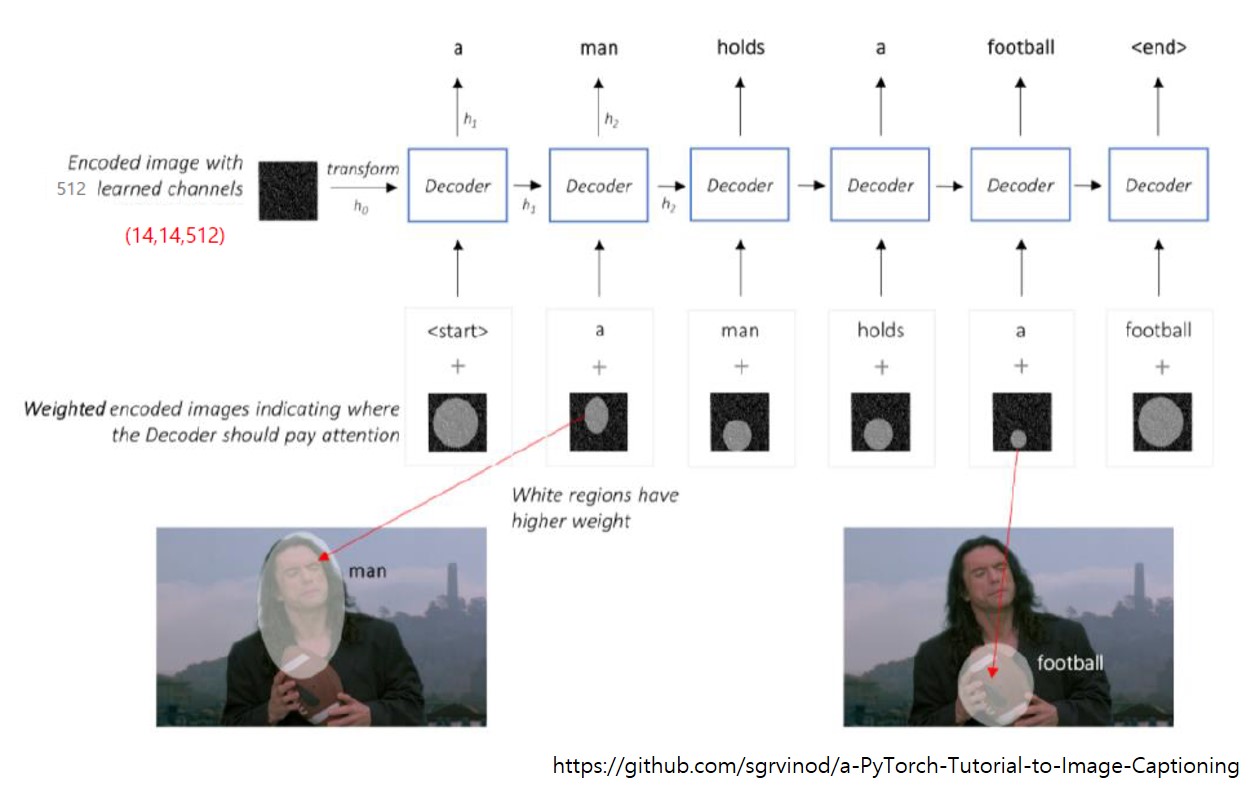
- 먼저, pretraind CNN 모델을 통해 image의 feature map을 얻습니다.
- 이 feature map을 입력으로 하여 LSTM의 첫번 째 hidden state와 cell state를 구하고, attention weighted encoding을 구합니다.
- 현재 timestep에서 계산된 attention weighted encoding과 hidden 및 cell state는 다음 timestep의 word를 생성하는데 사용됩니다.
이 논문에서 사용된 attention 구조는 hidden state와 weighted encoding을 element-wise하게 합한 다음 fc layer를 통과하는 것으로 구성되어 있는데, 이는 key와 query의 dot product를 통해 similarity를 계산하는 형태의 잘 알려진 Transformer와는 차이가 있습니다.
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
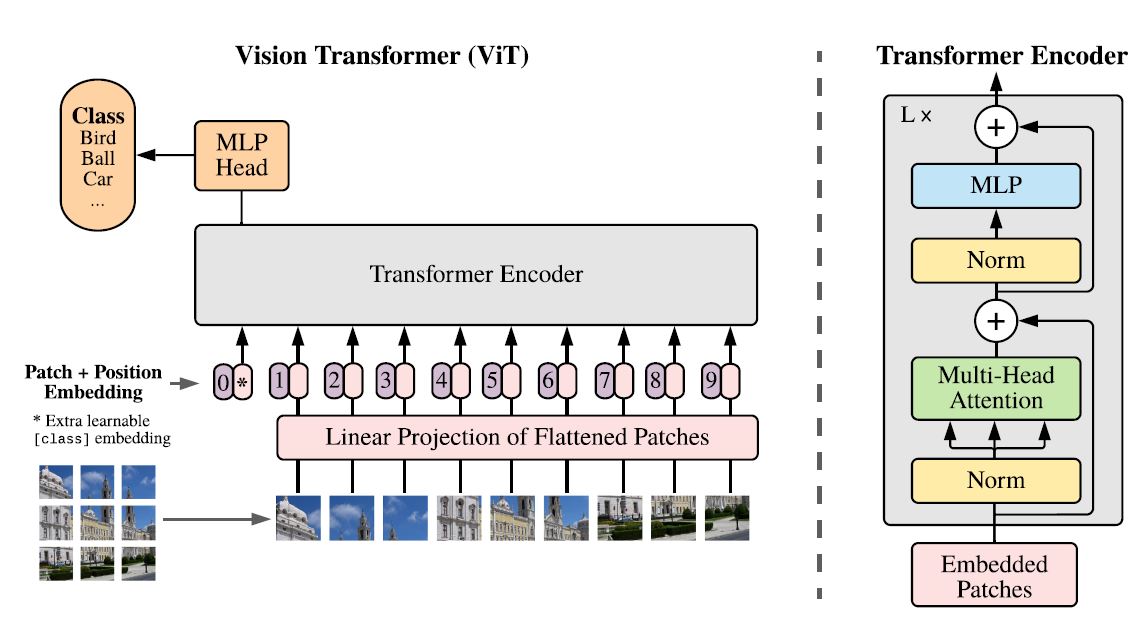
이 논문은 위 논문 제목보단 ViT(Vision Transformer)라는 이름으로 더 잘 알려져 있습니다. ViT에선 이미지를 patch 단위로 쪼개어 마치 sequence의 word embedding이 모델의 input으로 사용되는 것처럼 이미지의 patch들이 모델의 input으로 사용됩니다. 위 그림의 Linear Projection of Flattened Patches 부분이 NLP에서 사용되는 word embedding layer라 볼 수 있고, 여기서 정해진 embedding size가 transformer encoder의 각 layer에서 모두 동일하게 사용됩니다. Transformer Encoder의 구조는 Original Transformer(‘Attention is All You Need’)구조를 그대로 사용했다고 합니다.
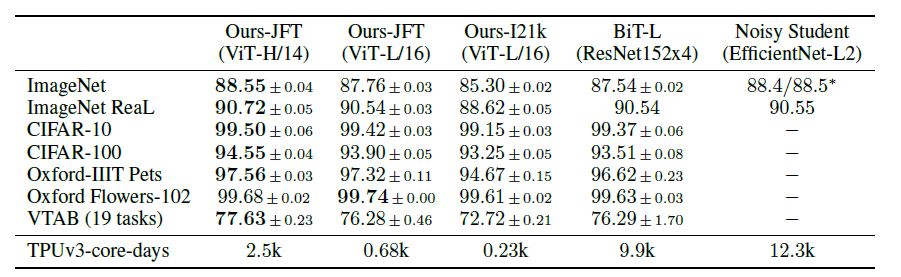
ViT를 사용하면 CNN의 Image에 특화된 inductive bias를 줄일 수 있고, kernel 단위로 local한 feature이 주로 학습되는 CNN과 달리 좀 더 global한 feature를 학습할 수 있다고 합니다. 논문에서 제시한 위 결과를 보면 ResNet152x4 을 사용한 BiT-L모델과 EfficientNet-L2를 사용한 Noisy Student모델 대비 ViT모델이 학습시간이 적게 소요되면서 여러 데이터셋에 대해 더 좋은 성능을 보임을 확인할 수 있습니다. 하지만, 이러한 성능향상은 기존 CNN모델 대비 더 많은 사전학습 데이터를 필요로 한다는 단점이 있기에 이를 개선하기 위해 일부 CNN layer와 함께 사용하는 연구들이 후속 연구로 많이 등장하고 있습니다.
<—————-작성 중—————->
Reference
paper :
Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions
MLP-Mixer: An all-MLP Architecture for Vision