NeRF : Neural Radiance Field(2)
이번 포스트에선 직전 NeRF 내용에 이어 NeRF와 관련된 후속 연구들에서 대해서 정리해보았습니다.
Baking Neural Radiance Fields for Real-Time View Synthesis
학습된 NeRF를 사용해서 view를 렌더링 하려면 ray별로 MLP를 타야하므로 MLP를 수백번 통과해야합니다. 이를 해결하기 위해 Sparse Neural Radiance Grid(SNeRG)에서는 학습 중에 MLP의 output을 미리 저장(“bake”한다고 함)하는 구조를 제안했고, 이를 통해 일반적인 하드웨어에서 real-time rendering이 가능하게 되었다고 합니다.
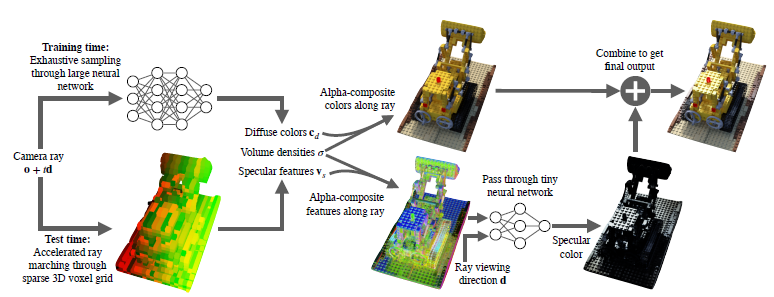
(*NeRF에서 density라고 했는데 이 논문에선 opacity로 혼용하고 있습니다. ‘진한정도’를 ‘투명한정도’로 바꿔서 표현한 것으로 생각됩니다.)
위 그림 중 Alpha-composite은 ray 위에 있는 color들을 weighted sum하는 과정을 말하고, 전체적인 순서는 다음과 같습니다.
- trained NeRF를 통해 sparse한 예측값들을 3D voxel grid에 저장해 둔다.
- 그러면 voxel엔 color, opacity, view dependent한 feature vector들이 저장될 것이다.
- 그리고 test 시, rendering할 땐 voxel에 저장된 color와 feature vector들을 weighted sum하게 되는데, feature vector가 view dependent하다고 했으므로 별도의 viewing direction과 함께 NN을 추가로 사용해 specular color 정보를 구한다.
- 그리고 최종 output은 voxel에 저장되어 있던 color의 weighted sum과 specular color의 합으로 구한다.
기존 NeRF에선 ray 위에 있는 3d point마다 NN을 통과해야 했는데, SNeRG에선 output이 될 2d 이미지의 픽셀마다 추가로 사용된 tiny NN만 통과하면 되기에 rendering 속도가 빨라지게 됩니다.
FastNeRF : High-Fidelity Neural Rendering at 200FPS
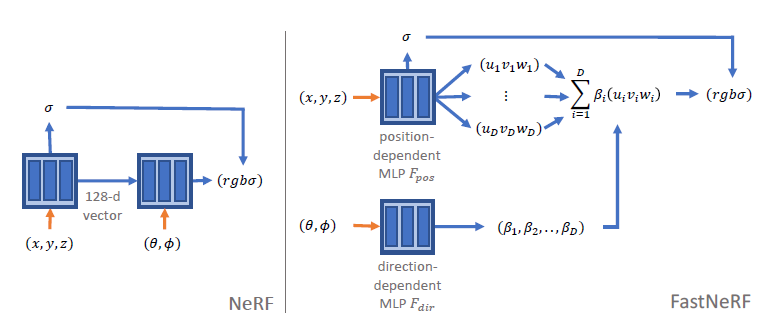 이 논문에선 position과 direction을 각각 input으로 하는 neural network 두 개를 사용하는 구조를 제안합니다. position과 direction에 각각 k, l개의 값이 사용된다고 할 때, NeRF의 memory complexity는 $O(k^3 l^2)$이었는데, FastNeRF에선 $O(k^3 \times (1+3D)+ l^2\times D)$로 줄어 들게 됩니다.
이 논문에선 position과 direction을 각각 input으로 하는 neural network 두 개를 사용하는 구조를 제안합니다. position과 direction에 각각 k, l개의 값이 사용된다고 할 때, NeRF의 memory complexity는 $O(k^3 l^2)$이었는데, FastNeRF에선 $O(k^3 \times (1+3D)+ l^2\times D)$로 줄어 들게 됩니다.
KiloNeRF : Speeding Up Neural Radiance Fields
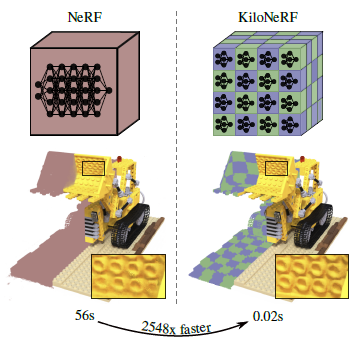
NeRF처럼 전체 scene을 하나의 큰 MLP로 represent하는 것이 아니라 scene 일부를 represent할 수 있는 작은 MLP를 수천개를 사용하는 구조입니다.

tiny NN을 사용해서 scene의 일부를 생성하고 합치면, 위 (a)처럼 이상한 물체들이 생기는 결과를 확인할 수 있는데, 이를 해결하기 위해 original nerf로 학습한 모델을 teacher로 하여 knowledge distillation방식으로 fine tuning을 진행했다고 합니다. distillation은 teacher의 output인 color와 density에 매칭하는 방식을 사용했고, 이렇게 하자 (b)처럼 artifacts를 제거한 결과를 얻을 수 있었습니다.
Learned Initializations for Optimizing Coordinate-Based Neural Representations
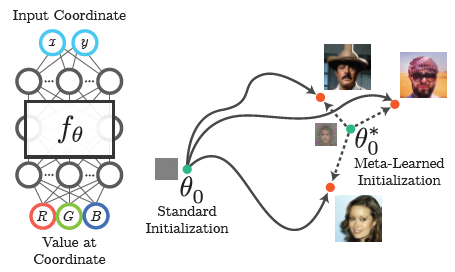
좌표를 입력으로 하여 rgb를 예측하는 모델은 동일한 물체에 대해 다양한 scene이 존재할 때, 이 중 일부를 학습하여 학습하지 않은 scene을 생성하는 역할을 합니다. 즉, novel view를 생성하고 싶은 물체마다 from scratch로 학습해야 하는데, 이게 너무 비효율적이니, initial weights parameter를 학습하기 위해 meta-learning algorithm을 활용한다는 컨셉의 논문입니다. meta-learning의 대표적인 논문인 MAML과 Reptile 방식이 사용됩니다.
PixelNeRF : Neural Radiance Fields from One or Few Images
기존에는 개별 scene들이 각각 optimize 됬는데, PixelNeRF에선 input view를 입력으로하여 novel view를 생성하는 학습 개념을 사용합니다. 이를 통해 적은 이미지만 사용해도 novel view를 생성할 수 있고, novel view를 생성하는 데 multi view의 이미지를 한 번에 사용하여 성능을 높일 수 있는 구조도 제안하고 있습니다.
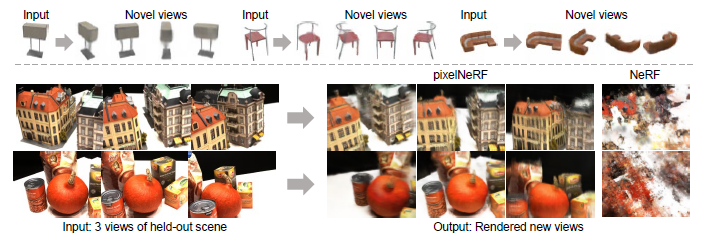
위 그림의 위, 아래는 각각 1 장, 3 장의 이미지를 사용해서 novel view를 생성했을 때의 성능을 보여줍니다. 적은 데이터만 사용했음에도 PixelNeRF는 NeRF에 비해 novel view를 잘 생성하고 있음을 보여줍니다.
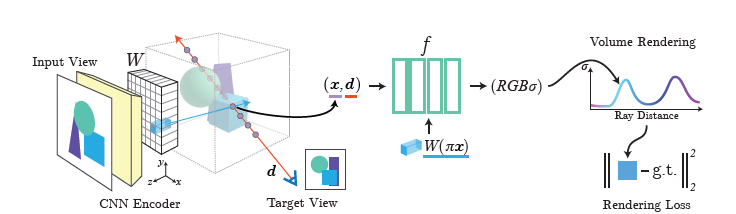
위는 이미지 한장(single view)으로 novel view를 생성하는 도식 입니다.
input이미지가 CNN Encoder를 통과하여 feature volume W를 구하고 target view를 생성하기 위한 ray 위에 있는 3d point x, viewing direction d를 같이 사용하여 $RGB\sigma$를 구하고 있습니다. weighted sum으로 predicted target view를 생성하는 과정은 NeRF와 동일합니다.
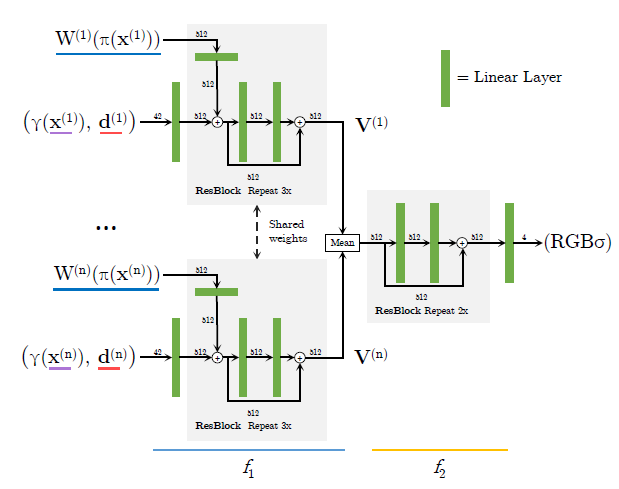
multi-view로 novel view를 생성하는 그림입니다.
single view그림에 있는 feature volume W를 합치는 부분이 view마다 진행되고, 평균한다음 추가로 fc layer를 통과하고 있습니다. $\gamma$는 sin, cos를 사용해서 input dimension을 늘려주는 positional encoding을 말합니다.
NeRF in Detail : Learning to Sample for View Synthesis
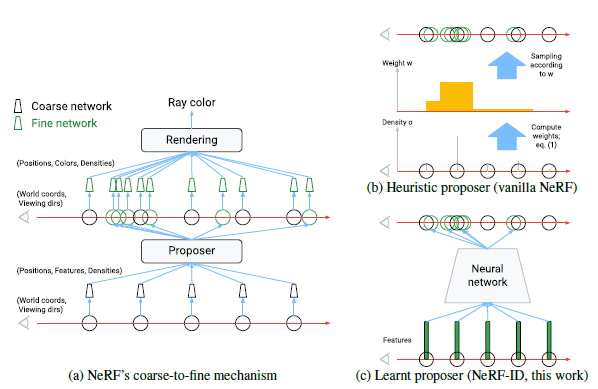
Original NeRF에서 사용했던 coarse-to-fine mechanism은 coarse network에서 예측한 weight를 사용해 sampling하는 Heuristic proposer방식이었습니다. 이 부분을 NeRF-ID에선 Learnt proposer 방식으로 대체합니다.
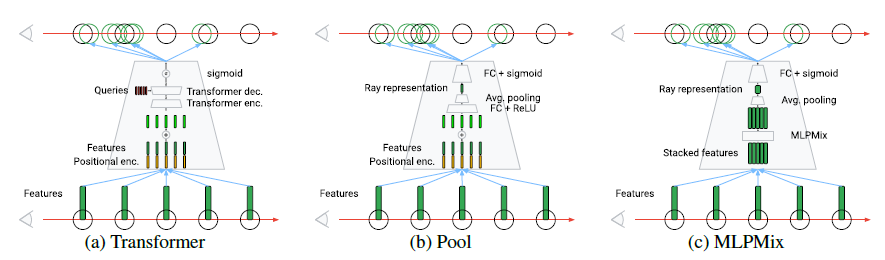
proposer를 학습하는 구조로 논문에선 위 세 가지를 제안하고, 각각에 대한 비교 실험을 진행합니다. (a)는 transformer구조를 활용한 것이고, (b)는 일반적인 fc layer와 pooling 구조를 사용한 그림 입니다. (c)에서는 MLP의 channel과 token을 각각 mixing하는 과정을 거치는 mlpmixer 구조를 활용하고 있습니다. (c)의 성능이 비교적 안정적이라 NeRF-ID에선 이를 기준 proposer로 사용했다고 합니다.
NeRF in the Wild : Neural Radiance Fields for Unconstrained Photo Collections
NeRF는 controlled setting에서 잘 동작하는데, NeRF-W에선 real-world에 사용할 수 있도록 이를 확장합니다.

논문에선 인터넷에서 찾아볼 수 있는 (a)와 같은 사진들을 활용해서 (b)와 같이 다양한 조명의 novel view를 rendering 한 결과를 제시합니다.
이미지의 feature를 disentangle하는 GAN 연구를 이용해 이미지의 appearance variation인 exposure, lighting, weather 같은 것들을 분리하고 동일 물체를 찍은 다양한 photo에서 shared appearance representation을 학습합니다. 이렇게 “static”과 “transient” component를 분리하고 static component를 사용하면 novel view를 생성할 수 있습니다.
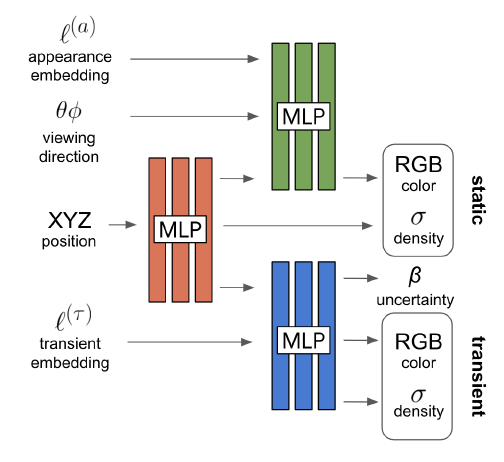
모델 구조는 위와 같습니다. Original NeRF처럼 position과 viewing direction을 입력으로 사용하는데, 여기에 appearance embedding을 같이 사용하여 static color, density를 생성하고, transient embedding을 같이 사용하여 transient color, density를 생성합니다.

NeRF-W는 위 처럼 static(a)과 transient(b)가 분리된 scene을 생성할 수 있고, 둘을 합쳐(c) 원본 이미지(d)와 reconstruction loss를 minimize하는 것으로 학습합니다. (e)는 제안 방법이 이미지의 anomalous region도 구분할 수 있다는 것을 보여줍니다.
Reference
paper :
Baking Neural Radiance Fields for Real-Time View Synthesis
FastNeRF : High-Fidelity Neural Rendering at 200FPS
KiloNeRF : Speeding Up Neural Radiance Fields
Learned Initializations for Optimizing Coordinate-Based Neural Representations
PixelNeRF : Neural Radiance Fields from One or Few Images
NeRF in Detail : Learning to Sample for View Synthesis
NeRF in the Wild : Neural Radiance Fields for Unconstrained Photo Collections
other :
PR-302: NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
[Seminar] NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
Lecture8 AAA738 SeungryongKim